



Retrieval-Augmented Generation (RAG) is an AI framework that enhances large language models (LLMs) by combining information retrieval with text generation. Instead of relying only on static training data, RAG systems fetch relevant information from external sources in real time, improving accuracy and reducing hallucinations.
As AI applications move from simple content generation to production-grade systems, understanding what RAG in AI is and how a RAG pipeline works has become essential for building reliable and scalable solutions.
What Is RAG in AI?
The RAG full form is Retrieval-Augmented Generation, which is a framework that improves language models by combining a Retriever and a Generator. The former extracts relevant information from a data source, while a generator uses that information to generate a response.
To break it down further, traditional LLMs answer only on the basis of their training data, while the RAG system answers using system and real-time data. Hence, these are more reliable for apps where accuracy matters.
What Is the Goal of RAG in AI Systems?
The main goal of RAG is to elevate the quality and reliability of AI outputs. Some other objectives include:
- Reduce Hallucinations: LLMs generate incorrect information when they are unsure, but RAG provides factual context to avoid it.
- Enable Domain-Specific Knowledge: Organizations can train LLMs with their internal documents so their responses become more relevant.
- Provides Latest Information: RAG enables models to use recent data for the responses without retraining.
- Improves User Trust in AI Systems: Using RAG, AI systems can provide real data that users will trust the system more.
What Is a RAG Pipeline?
RAG Piepelije means the step-by-step workflow that fetches relevant data and gives it to the language model for response generation.
A RAG pipeline includes the following stages:
- Data Ingestion: Documents, PDFs, databases, or web content are collected and prepared.
- Data Chunking: It breaks large documents into smaller segments to improve retrieval accuracy.
- Embedding Generation: It converts every chunk into a vector representation through embedding models.
- Vector Stage: It stores embeddings in a vector database for efficient search.
- Query Processing: When a user asks a question, the system converts it into an embedding.
- Retrieval: It fetches relevant data chunks on the basis of a similarity search.
- Augmented Generation: It passes the retrieved context to the LLM who generates the answer.
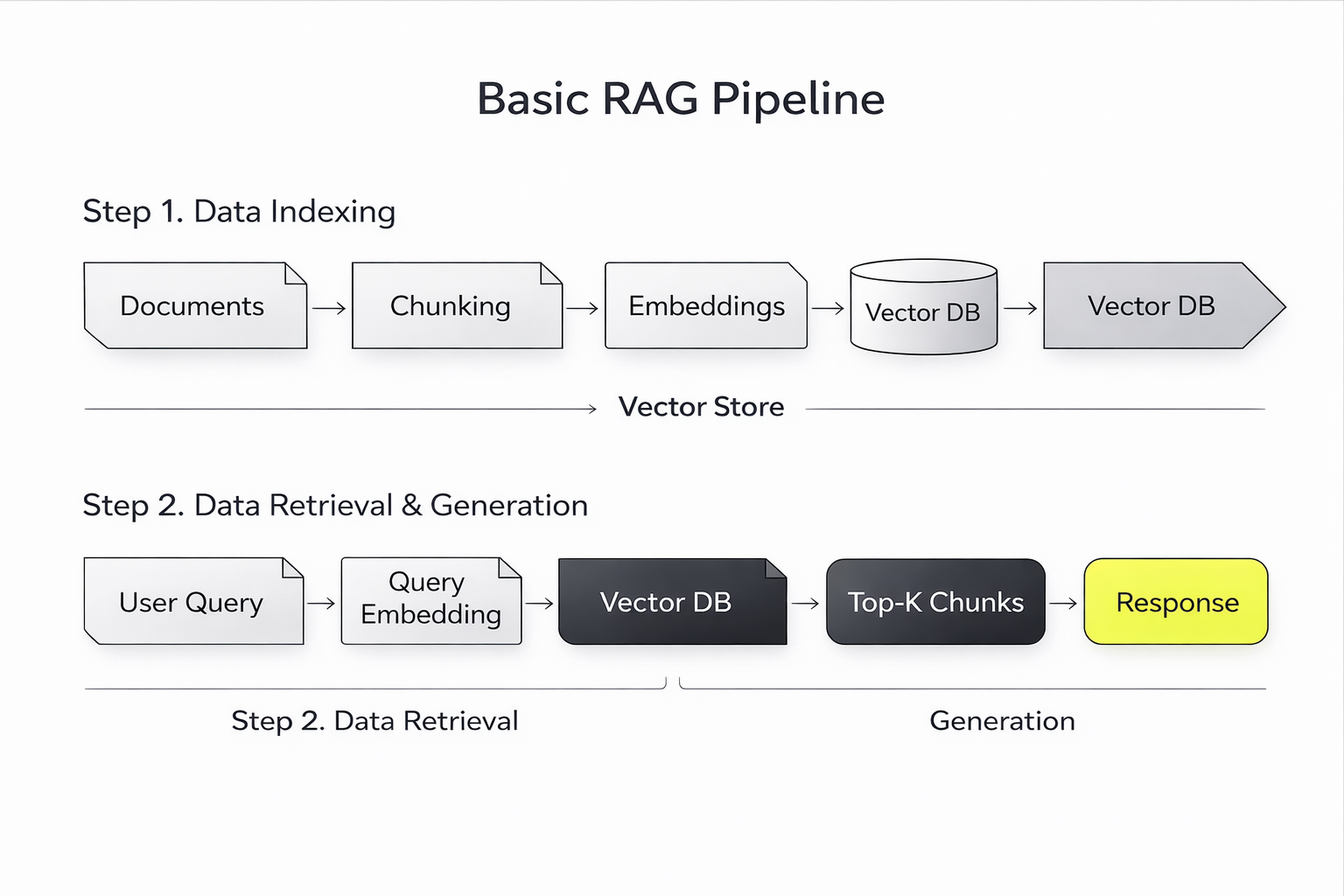
RAG pipeline diagram showing document chunking, embeddings, vector database retrieval, and LLM response generation
This pipeline is responsible for the accurate retrieval of relevant information instead of assumptions.
How RAG Works in LLMs
To understand the working of RAG, let's take the example of a customer support AI system.
Without RAG such a model will respond on the basis of general knowledge which can be vague or incorrect.
Here's where using an RAG, the system will fetch company documentation and will answer using that data. It leads to more accurate answers, context-aware responses, and a better user experience. Thus, RAG converts a general-purpose AI model into a domain-specific system.
RAG vs Traditional LLM Approach
Hence, traditional LLMs help with general tasks while RAG systems are suitable for production environments.
Applications of RAG in AI Systems
Many industries use RAG widely where accurate and context-aware responses are needed. The following is a list of the same:
- Enterprise Knowledge Assistants: AI systems use internal documents for answering employee queries.
- Customer Support Automation: RAG helps to generate accurate responses based on company FAQs, policies, and documentation.
- Healthcare AI: AI systems retrieve medical literature or patient data to assist with decision-making.
- Legal and Compliance Tools: Due to RAG, AI can reference regulations and legal documents.
- AI Coding Assistants: RAG models retrieve codebase context for giving relevant coding suggestions.
Such applications are advancing, and so their use cases; hence, RAG is becoming a standard architecture for AI systems.
Challenges in RAG Implementation
Though RAG improves AI performance, it leads to complexity as well.
Some of them include:
- Data Quality Issues: Poor or obsolete data leads to inaccurate outputs.
- Retrieval Accuracy: If the retriever retrieves irrelevant data, then the final response suffers.
- Latency: RAG pipelines can increase the response time due to retrieval steps.
- Context Limitations: LLMs have limits on how much context they can process.
Hence these challenges need a proper system design, optimization and skills to tackle.
Why Are RAG Skills In Demand?
AI systems are greatly in use, and companies actively seek professionals developing reliable LLM applications.
Thus, it has become a core skill in various areas like:
- LLM application development
- AI system design
- Data engineering
- Enterprise AI solutions
Thus, as people have shifted from using tools to building AI systems, professionals equipped to optimize and work with RAG pipelines will gain a competitive edge.
How to Learn RAG and LLM Systems?
Learning RAG needs an understanding of various aspects, such as:
- LLMs
- Embeddings and vector databases
- Retrieval systems
- Prompt and context design
- AI deployment workflows
Hence, structured learning programs equip candidates to understand how these work together and their industrial execution.
Lately, the PG Certificate in AI-Driven LLM, SLM, Agentic & RAG Development by IIT Jammu is gaining vogue. It is because it focuses on building real-world AI systems using retrieval-based architectures and preparing candidates for industry roles.
Future of RAG in AI
RAG is anticipated to become the foundational model in AI development. Some of the popular trends include:
- integration with agentic AI systems
- real-time enterprise AI applications
- improved retrieval techniques
- hybrid systems combining RAG and fine-tuning
As AI systems are becoming complex, a retrieval-based approach will act as an asset to ensure reliability. nva
TL; DR
RAG addresses some of the biggest limitations of LLMs, which is the lack of real-time yet context-specific knowledge. Hence, AI systems using RAG lead to accurate, relevant, and reliable outputs.
Thus, for AI learners and professionals, understanding RAG pipelines is necessary to build production-ready applications. As the adoption increases, so does the demand for professionals proficient in it to build modern AI systems.
FAQs: RAG in AI and RAG Pipeline
What does RAG mean in LLM?
RAG stands for Retrieval-Augmented Generation. In LLMs, it refers to a framework that combines a retrieval system with a language model to generate responses using external and real-time data, improving accuracy and reducing hallucinations.
Is the Claude Project a RAG?
Claude itself is a large language model, not a RAG system by default. However, it can be integrated with retrieval systems and external data sources to function as part of a RAG pipeline in enterprise or custom AI applications.
What are the types of RAG in AI?
RAG systems can be implemented in different ways depending on the use case. Common approaches include basic RAG (simple retrieval and generation), hybrid RAG (combining keyword and vector search), and advanced RAG systems that use techniques like reranking, filtering, or multi-step retrieval to improve accuracy.
What is the difference between RAG and RAG pipeline?
RAG is the overall framework that combines retrieval and generation. A RAG pipeline is the step-by-step process used to implement this framework, including stages like data ingestion, embedding, retrieval, and response generation.
How does a RAG pipeline improve LLM accuracy?
A RAG pipeline improves accuracy by retrieving relevant external data and providing it as context to the LLM. This helps reduce hallucinations and ensures responses are based on real and up-to-date information.
When should you use RAG in AI applications?
RAG is best used when applications require accurate, real-time, or domain-specific information, such as customer support systems, enterprise knowledge bases, healthcare tools, and legal AI solutions.


PG Certificate Program in AI-ML Engineering with LLM, SLM & Agentic Development
IIT Jammu
Learn to Build Domain-Specific LLMs, SLMs & Production-Ready RAG Systems

%20in%20AI.png)
.avif)
